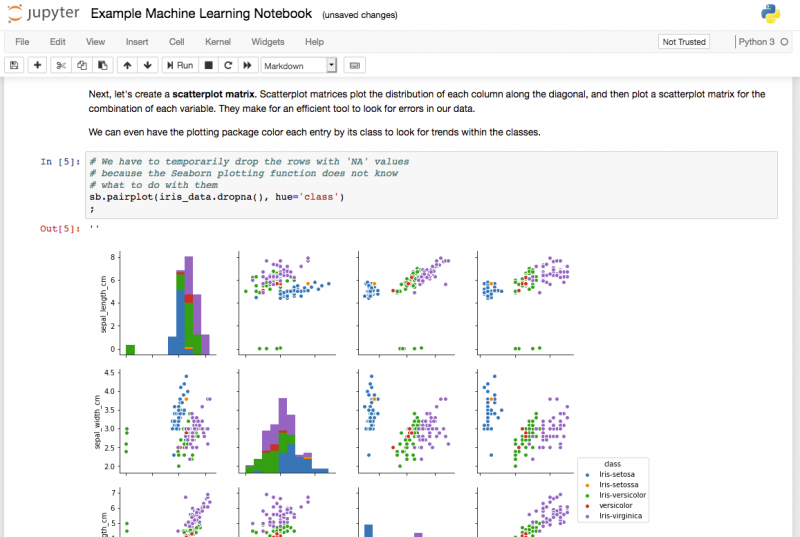
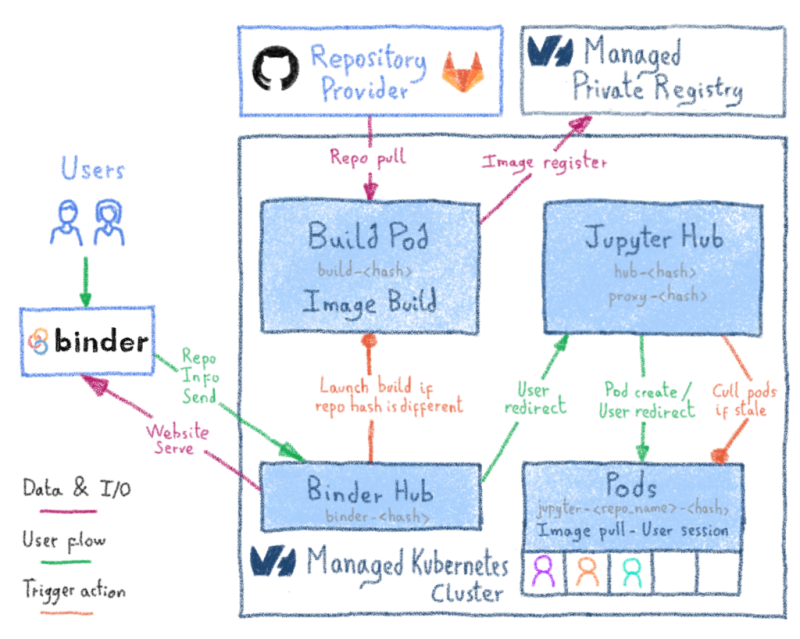
Jerem: Agile-бот
В OVHCloud мы открываем исходный код для нашего проекта «Agility Telemetry». Джерем , как наш сборщик данных, является основным компонентом этого проекта. Джерем регулярно очищает нашу JIRA и извлекает определенные показатели для каждого проекта. Затем он пересылает их в наше приложение для длительного хранения, платформу данных метрик OVHCloud .

Чтобы помочь вам понять наши цели для Jerem , нам нужно объяснить некоторые концепции Agility, которые мы будем использовать. Во-первых, мы составим техническую ежеквартальную дорожную карту для продукта, в которой изложены все функции, которые мы планируем выпускать каждые три месяца. Это то, что мы называем эпосом .
ЧДля каждой эпопеи мы определяем задачи, которые необходимо будет выполнить. Для всех этих задач мы затем оцениваем сложность задач с помощью очков истории во время сеанса подготовки команды. Сюжетная точка отражает усилия, необходимые для выполнения конкретной задачи JIRA.
Затем, чтобы продвинуть нашу дорожную карту, мы будем проводить регулярные спринты, которые соответствуют периоду в десять дней , в течение которого команда выполнит несколько задач. Количество очков истории, набранных в спринте, должно соответствовать или быть близким к скорости команды . Другими словами, среднее количество очков истории, которое команда может набрать за день.
Однако во время спринтов могут неожиданно возникнуть другие срочные задачи. Это то, что мы называем препятствием . Например, нам может потребоваться помощь клиентам, исправление ошибок или срочные инфраструктурные задачи.
В OVH мы используем JIRA для отслеживания нашей активности. Наш Jerem бот обрывки наших проектов из JIRA и экспорта всех необходимых данных для нашей OVHCloud Метрики платформы данных . Джерем также может передавать данные в любую базу данных, совместимую с Warp 10. В Grafana вы просто запрашиваете платформу Metrics (используя источник данных Warp10 ), например, с помощью нашей панели управления программами . Все ваши KPI теперь доступны на красивой панели инструментов!
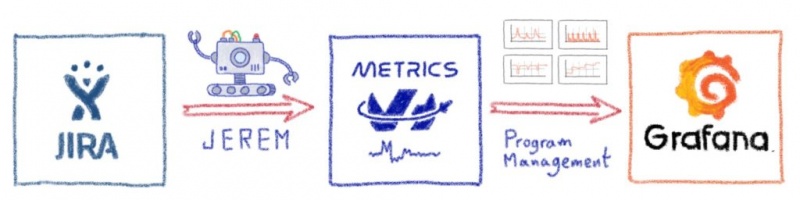
Теперь, когда у нас есть обзор основных задействованных концепций Agility, давайте погрузимся в Джерема! Как преобразовать эти концепции гибкости в показатели? Прежде всего, мы извлечем все показатели, относящиеся к эпикам (т.е. новым функциям). Затем мы подробно рассмотрим метрики спринта.
Эпические данные
Чтобы объяснить эпические метрики Джерема, мы начнем с создания новой. В этом примере мы назвали это Agile Telemetry. Мы добавляем лейбл Q2-20, что означает, что мы планируем выпустить его во втором квартале. Чтобы записать эпопею с Джеремом, вам нужно установить четверть для окончательной доставки! Затем мы просто добавим четыре задачи, как показано ниже:
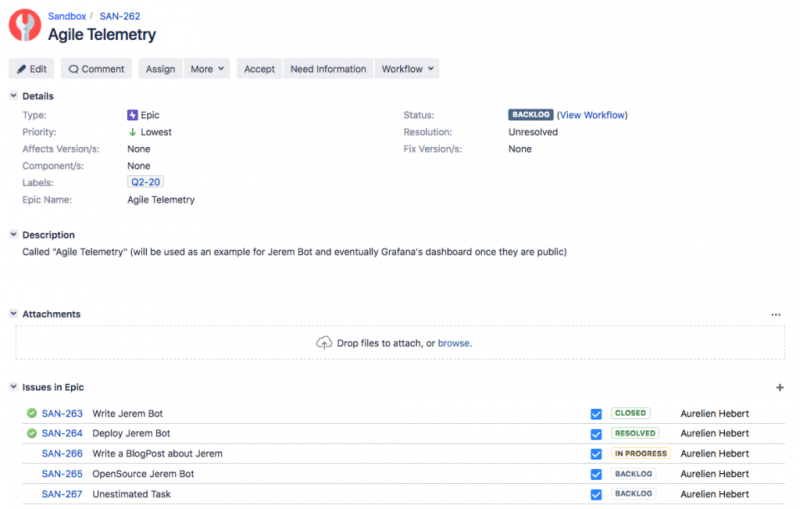
Чтобы получить метрики, нам нужно оценить каждую отдельную задачу. Мы сделаем это вместе на подготовительных сессиях. В этом примере у нас есть собственные очки истории для каждой задачи. Например, мы оценили write a BlogPost about Jeremзадачу на 3.
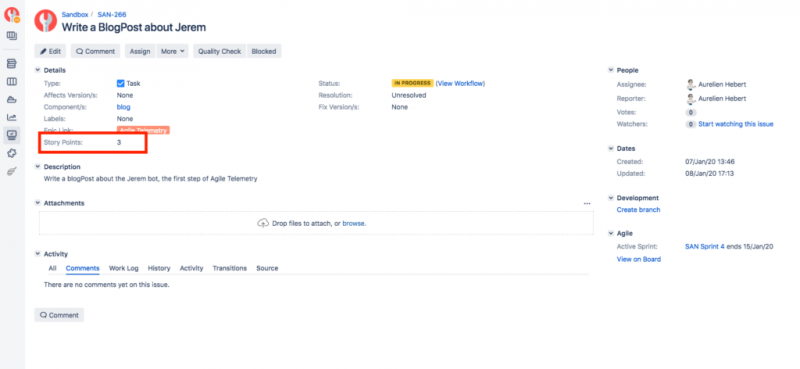
В результате у Джерема теперь есть все необходимое, чтобы начать сбор эпических показателей. В этом примере представлены пять показателей:
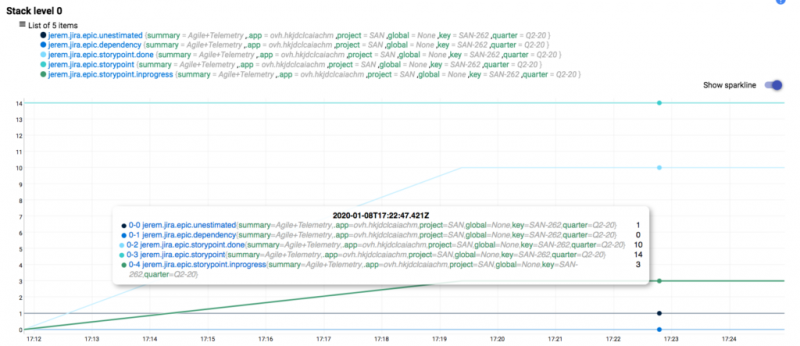
Таким образом, для каждого эпика в проекте Джерем собирает пять уникальных показателей.
Для выполнения грандиозных задач мы работаем по спринту . Выполняя спринты, мы хотим подробно рассказать о наших достижениях . Вот почему Джерем тоже собирает данные о спринтах!
Итак, давайте откроем новый спринт в JIRA и начнем работать над нашей задачей. Это дает нам следующее представление JIRA:
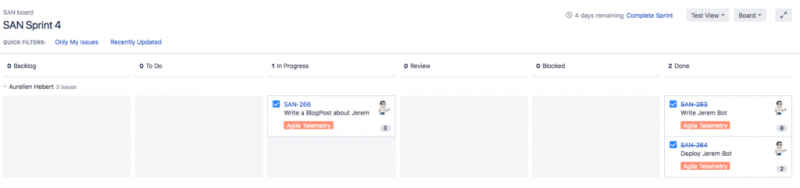
Джерем собирает следующие показатели для каждого спринта:
Как вы можете видеть в представлении «Показатели» выше, мы будем записывать каждую метрику спринта дважды. Мы делаем это, чтобы быстро просмотреть активный спринт, поэтому мы используем метку «текущий». Это также позволяет нам запрашивать прошлые спринты, используя настоящее имя спринта. Конечно, активный спринт также можно запросить по его имени.
Запуск спринта означает, что вам нужно знать все задачи, над которыми вам придется работать в течение следующих нескольких дней. Но как мы можем отслеживать и измерять незапланированные задачи? Например, очень срочное для вашего менеджера или товарища по команде, которому нужна небольшая помощь?
Мы можем добавить в JIRA специальные билеты, чтобы отслеживать выполнение этой задачи. Это то, что мы называем «препятствием». Они маркируются в соответствии с их природой. Если, например, постановка требует вашего внимания, то это препятствие «Инфра». Вы также получите метрики для «Всего» (все виды препятствий), «Избыточности» (незапланированные задачи), «Поддержка» (помощь товарищам по команде) и «Исправление ошибок или другое» (для всех других видов препятствий).
Каждое препятствие принадлежит активному спринту, в котором оно было закрыто. Чтобы закрыть препятствие, вам нужно только пометить его как «Готово» или «Закрыто».
Мы также получаем такие показатели, как:
TYPE соответствует виду зафиксированного препятствия. Поскольку мы не обнаружили никаких реальных препятствий, Джерем собирает только totalметрики.
Чтобы начать запись препятствий, мы просто создаем новую задачу JIRA, в которую добавляем метку «препятствие». Мы также устанавливаем его характер и фактическое время, потраченное на это.
В качестве препятствия мы также извлекаем глобальные метрики, которые всегда записывает Джерем:
Нам нравится создавать информационные панели Grafana! Они дают команде и менеджеру много информации о ключевых показателях эффективности. Лучшее в этом для меня, как разработчика, — это то, что я понимаю, почему хорошо выполнять задачу JIRA!
На нашей первой панели управления Grafana вы найдете все лучшие KPI для управления программами. Начнем с глобального обзора:
Обзор квартальных данных
Здесь вы найдете текущую эпопею. Вы также найдете глобальные ключевые показатели эффективности команды, такие как предсказуемость, скорость и статистика препятствий. Здесь происходит волшебство! При правильном заполнении эта панель инструментов точно покажет вам, что ваша команда должна выполнить в текущем квартале. Это означает, что у вас есть быстрый доступ ко всем актуальным темам. Вы также сможете увидеть, не ожидается ли, что ваша команда будет работать по слишком большому количеству вопросов, чтобы вы могли быстро принять меры и отложить некоторые из новых функций.
Данные активного спринта
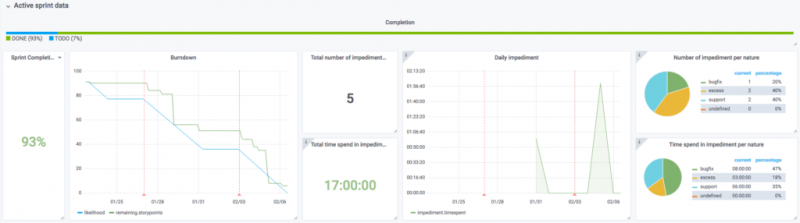
Активная панель данных спринта часто оказывается отличной поддержкой во время наших ежедневных встреч. На этой панели мы получаем краткий обзор достижений команды и можем установить время, потраченное на параллельные задачи.
Подробные данные
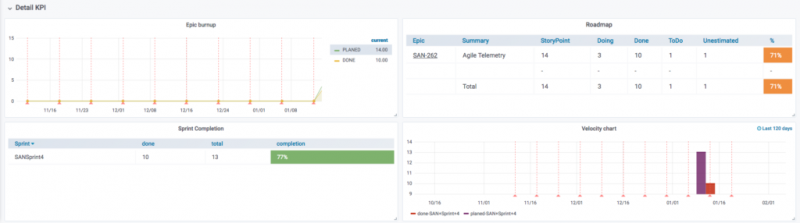
В последней части представлены более подробные данные. Используя переменную epic Grafana, мы можем проверять конкретные эпики, а также завершение более глобальных проектов. У вас также есть velocity chart, который отображает прошлый спринт и сравнивает ожидаемые баллы истории с фактически завершенными.
Настройка Jerem и автоматическая загрузка данных управления программами дают нам много полезного. Мне как разработчику это очень нравится, и я быстро привык отслеживать в JIRA гораздо больше событий, чем раньше. Вы можете напрямую видеть влияние ваших задач. Например, вы видите, как быстро продвигается дорожная карта, и можете определить любые узкие места, которые создают препятствия. Затем эти узкие места становятся эпопеями. Другими словами, как только мы начинаем использовать Jerem, мы просто заполняем его автоматически! Надеюсь, вам тоже понравится! Если у вас есть отзывы, мы будем рады их услышать.
Концепции Agility с точки зрения разработчика
Чтобы помочь вам понять наши цели для Jerem , нам нужно объяснить некоторые концепции Agility, которые мы будем использовать. Во-первых, мы составим техническую ежеквартальную дорожную карту для продукта, в которой изложены все функции, которые мы планируем выпускать каждые три месяца. Это то, что мы называем эпосом .
ЧДля каждой эпопеи мы определяем задачи, которые необходимо будет выполнить. Для всех этих задач мы затем оцениваем сложность задач с помощью очков истории во время сеанса подготовки команды. Сюжетная точка отражает усилия, необходимые для выполнения конкретной задачи JIRA.
Затем, чтобы продвинуть нашу дорожную карту, мы будем проводить регулярные спринты, которые соответствуют периоду в десять дней , в течение которого команда выполнит несколько задач. Количество очков истории, набранных в спринте, должно соответствовать или быть близким к скорости команды . Другими словами, среднее количество очков истории, которое команда может набрать за день.
Однако во время спринтов могут неожиданно возникнуть другие срочные задачи. Это то, что мы называем препятствием . Например, нам может потребоваться помощь клиентам, исправление ошибок или срочные инфраструктурные задачи.
Как работает Джерем
В OVH мы используем JIRA для отслеживания нашей активности. Наш Jerem бот обрывки наших проектов из JIRA и экспорта всех необходимых данных для нашей OVHCloud Метрики платформы данных . Джерем также может передавать данные в любую базу данных, совместимую с Warp 10. В Grafana вы просто запрашиваете платформу Metrics (используя источник данных Warp10 ), например, с помощью нашей панели управления программами . Все ваши KPI теперь доступны на красивой панели инструментов!
Откройте для себя показатели Jerem
Теперь, когда у нас есть обзор основных задействованных концепций Agility, давайте погрузимся в Джерема! Как преобразовать эти концепции гибкости в показатели? Прежде всего, мы извлечем все показатели, относящиеся к эпикам (т.е. новым функциям). Затем мы подробно рассмотрим метрики спринта.
Эпические данные
Чтобы объяснить эпические метрики Джерема, мы начнем с создания новой. В этом примере мы назвали это Agile Telemetry. Мы добавляем лейбл Q2-20, что означает, что мы планируем выпустить его во втором квартале. Чтобы записать эпопею с Джеремом, вам нужно установить четверть для окончательной доставки! Затем мы просто добавим четыре задачи, как показано ниже:
Чтобы получить метрики, нам нужно оценить каждую отдельную задачу. Мы сделаем это вместе на подготовительных сессиях. В этом примере у нас есть собственные очки истории для каждой задачи. Например, мы оценили write a BlogPost about Jeremзадачу на 3.
В результате у Джерема теперь есть все необходимое, чтобы начать сбор эпических показателей. В этом примере представлены пять показателей:
: общее количество очков истории, необходимых для завершения этой эпопеи. Значение здесь 14 (сумма всех очков эпической истории). Этот показатель будет развиваться каждый раз, когда эпик обновляется путем добавления или удаления задач.jerem.jira.epic.storypoint
: количество выполненных задач. В нашем примере мы уже выполнилиjerem.jira.epic.storypoint.done
иWrite Jerem bot
, поэтому мы уже выполнили восемь пунктов истории.Deploy Jerem Bot
: количество «выполняемых» задач, напримерjerem.jira.epic.storypoint.inprogress
.Write a BlogPost about Jerem
: количество неоцененных задач, какjerem.jira.epic.unestimated
в нашем примере.Unestimated Task
: количество задач, у которых есть метки зависимостей, указывающие, что они являются обязательными для других эпиков или проектов.jerem.jira.epic.dependency
Таким образом, для каждого эпика в проекте Джерем собирает пять уникальных показателей.
Данные спринта
Для выполнения грандиозных задач мы работаем по спринту . Выполняя спринты, мы хотим подробно рассказать о наших достижениях . Вот почему Джерем тоже собирает данные о спринтах!
Итак, давайте откроем новый спринт в JIRA и начнем работать над нашей задачей. Это дает нам следующее представление JIRA:
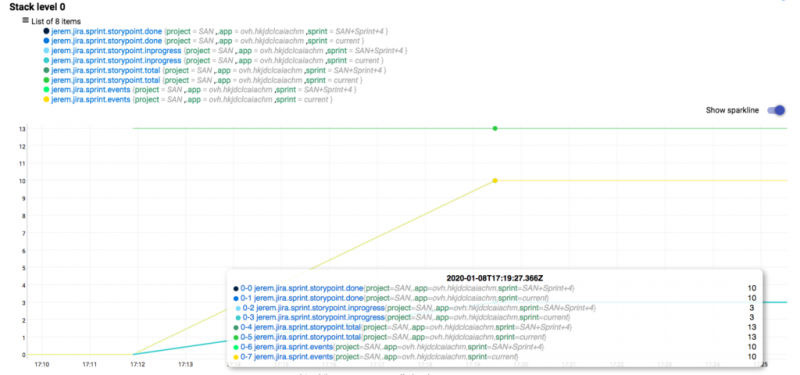
Джерем собирает следующие показатели для каждого спринта:
: общее количество очков истории, набранных в спринт.erem.jira.sprint.storypoint.total
: сюжетные точки, которые в настоящее время выполняются в рамках спринта.jerem.jira.sprint.storypoint.inprogress
: количество очков истории, набранных на данный момент за спринт.jerem.jira.sprint.storypoint.done
: даты начала и окончания спринта, записанные как строковые значения Warp10.jerem.jira.sprint.events
Как вы можете видеть в представлении «Показатели» выше, мы будем записывать каждую метрику спринта дважды. Мы делаем это, чтобы быстро просмотреть активный спринт, поэтому мы используем метку «текущий». Это также позволяет нам запрашивать прошлые спринты, используя настоящее имя спринта. Конечно, активный спринт также можно запросить по его имени.
Данные о препятствиях
Запуск спринта означает, что вам нужно знать все задачи, над которыми вам придется работать в течение следующих нескольких дней. Но как мы можем отслеживать и измерять незапланированные задачи? Например, очень срочное для вашего менеджера или товарища по команде, которому нужна небольшая помощь?
Мы можем добавить в JIRA специальные билеты, чтобы отслеживать выполнение этой задачи. Это то, что мы называем «препятствием». Они маркируются в соответствии с их природой. Если, например, постановка требует вашего внимания, то это препятствие «Инфра». Вы также получите метрики для «Всего» (все виды препятствий), «Избыточности» (незапланированные задачи), «Поддержка» (помощь товарищам по команде) и «Исправление ошибок или другое» (для всех других видов препятствий).
Каждое препятствие принадлежит активному спринту, в котором оно было закрыто. Чтобы закрыть препятствие, вам нужно только пометить его как «Готово» или «Закрыто».
Мы также получаем такие показатели, как:
: количество препятствий, возникших во время спринта.jerem.jira.impediment.TYPE.count
: количество времени, затраченного на устранение препятствий во время спринта.jerem.jira.impediment.TYPE.timespent
TYPE соответствует виду зафиксированного препятствия. Поскольку мы не обнаружили никаких реальных препятствий, Джерем собирает только totalметрики.
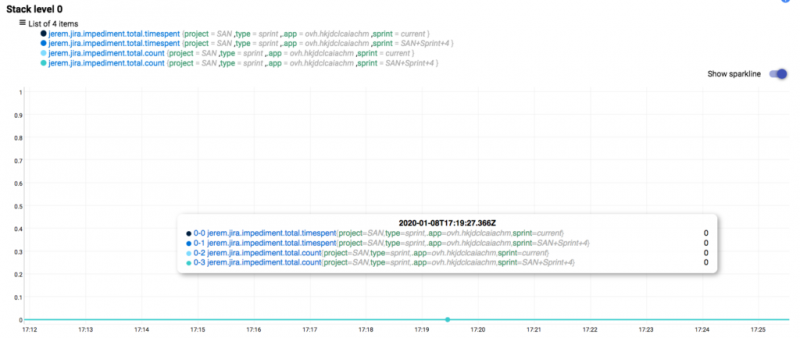
Чтобы начать запись препятствий, мы просто создаем новую задачу JIRA, в которую добавляем метку «препятствие». Мы также устанавливаем его характер и фактическое время, потраченное на это.
В качестве препятствия мы также извлекаем глобальные метрики, которые всегда записывает Джерем:
- jerem.jira.impediment.total.created: время, затраченное с даты создания на устранение препятствия. Это позволяет нам получить общее количество препятствий. Мы также можем записывать все действия с препятствиями, даже вне спринтов.
Для одного проекта Jira, как в нашем примере, вы можете ожидать около 300 показателей. Это может увеличиваться в зависимости от эпика, который вы создаете и помечаете в Jira, и того, который вы закрываете.
Панель управления Grafana
Нам нравится создавать информационные панели Grafana! Они дают команде и менеджеру много информации о ключевых показателях эффективности. Лучшее в этом для меня, как разработчика, — это то, что я понимаю, почему хорошо выполнять задачу JIRA!
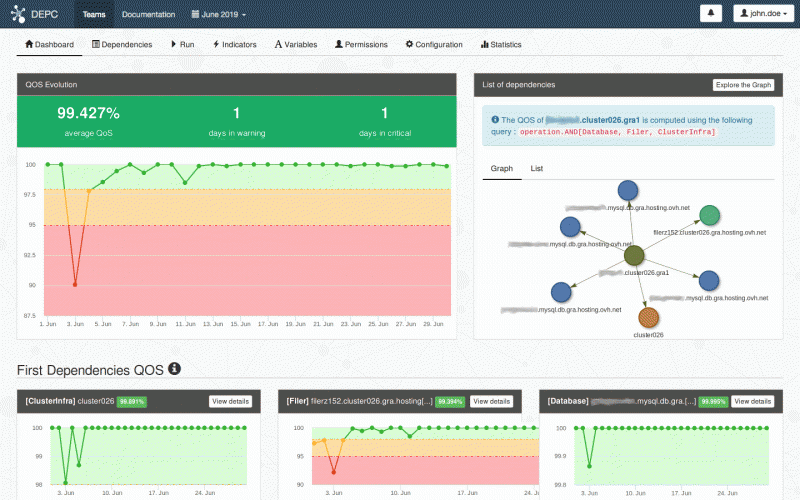
На нашей первой панели управления Grafana вы найдете все лучшие KPI для управления программами. Начнем с глобального обзора:
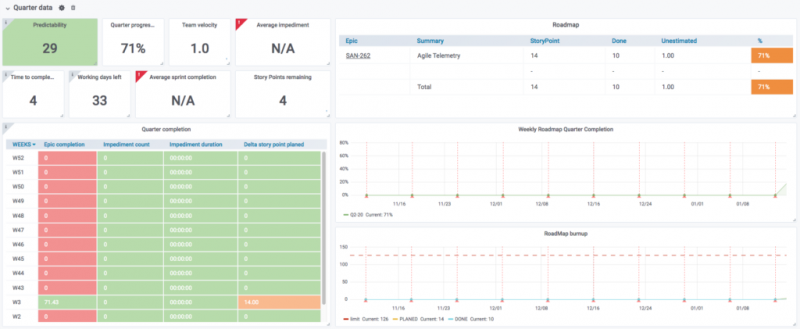
Обзор квартальных данных
Здесь вы найдете текущую эпопею. Вы также найдете глобальные ключевые показатели эффективности команды, такие как предсказуемость, скорость и статистика препятствий. Здесь происходит волшебство! При правильном заполнении эта панель инструментов точно покажет вам, что ваша команда должна выполнить в текущем квартале. Это означает, что у вас есть быстрый доступ ко всем актуальным темам. Вы также сможете увидеть, не ожидается ли, что ваша команда будет работать по слишком большому количеству вопросов, чтобы вы могли быстро принять меры и отложить некоторые из новых функций.
Данные активного спринта
Активная панель данных спринта часто оказывается отличной поддержкой во время наших ежедневных встреч. На этой панели мы получаем краткий обзор достижений команды и можем установить время, потраченное на параллельные задачи.
Подробные данные
В последней части представлены более подробные данные. Используя переменную epic Grafana, мы можем проверять конкретные эпики, а также завершение более глобальных проектов. У вас также есть velocity chart, который отображает прошлый спринт и сравнивает ожидаемые баллы истории с фактически завершенными.
Панель управления Grafana доступна напрямую в проекте Jerem. Вы можете импортировать его прямо в Grafana, если у вас настроен действительный источник данных Warp 10.
Чтобы панель управления работала должным образом, вам необходимо настроить переменную проекта Grafana в виде списка WarpScript [ 'SAN' 'OTHER-PROJECT' ]. Если наш программный менеджер может это сделать, я уверен, вы сможете!
Настройка Jerem и автоматическая загрузка данных управления программами дают нам много полезного. Мне как разработчику это очень нравится, и я быстро привык отслеживать в JIRA гораздо больше событий, чем раньше. Вы можете напрямую видеть влияние ваших задач. Например, вы видите, как быстро продвигается дорожная карта, и можете определить любые узкие места, которые создают препятствия. Затем эти узкие места становятся эпопеями. Другими словами, как только мы начинаем использовать Jerem, мы просто заполняем его автоматически! Надеюсь, вам тоже понравится! Если у вас есть отзывы, мы будем рады их услышать.